WebCopy 将扫描指定的网站并将其内容下载到您的硬盘上。
WebCopy 将检查网站的 HTML 标记,并尝试发现所有链接的资源,如其他页面,图像,视频,文件下载 – 任何东西和一切。
它将下载所有这些资源,并继续搜索更多。以这种方式,WebCopy 可以“抓取”整个网站,并下载其看到的所有内容,以创建源网站。
填写源站网址,开始扒~~~~扒!扒死它!
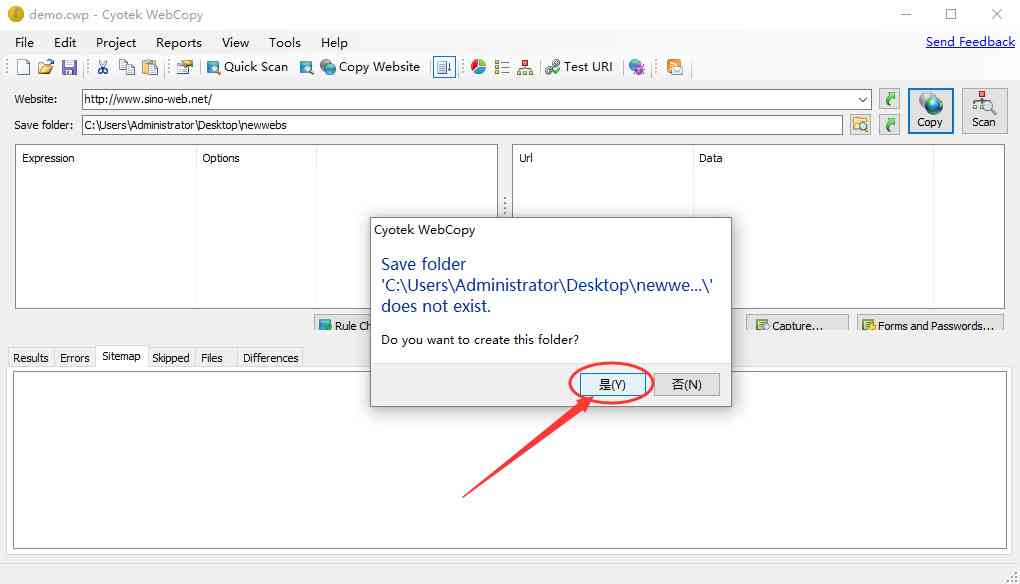
点击 copy 后会运行然后可能出现假死状态,需要等待程序抓取完成。
抓取完成!看看路径以及 css 或者其他的都是否一致。
关于抓取时间的话,取决于你要扒的网站的大小,源站大且图片多的话,emmm 那时间会久一点。
官网:https://www.cyotek.com/cyotek-webcopy (暂时没找到汉化包,有哪位大佬可以汉化一下放出来呀~~~在此谢过!)
– 另外支持多开!